🎧 AI: 3초만 쳐다보면 알아서 해드려요! 오늘 레터는 이런 내용이에요 💌:
- AI는 내가 누구랑 대화 중인지 어떻게 알았을까?
- 원하는 사람 목소리만 들려주는 노이즈캔슬링
- 동시에 여러 목소리를 통역해 주는 헤드폰
|
|
|
상대를 쳐다보면 그 사람 목소리만 들리는 헤드폰
vs.
여럿이 하는 말을 동시통역해 주는 헤드폰
헤드폰의 노이즈캔슬링 기능이 진화하고 있습니다. 지난주 레터에서, 우리는 ‘듣고 싶은 말만 하는’ 챗GPT를 살펴보았는데요. 오늘은 <듣고 싶은 말만 들려주는 AI>와 <말하는 대로 들려주는 AI>에 대해 알아보겠습니다. |
|
|
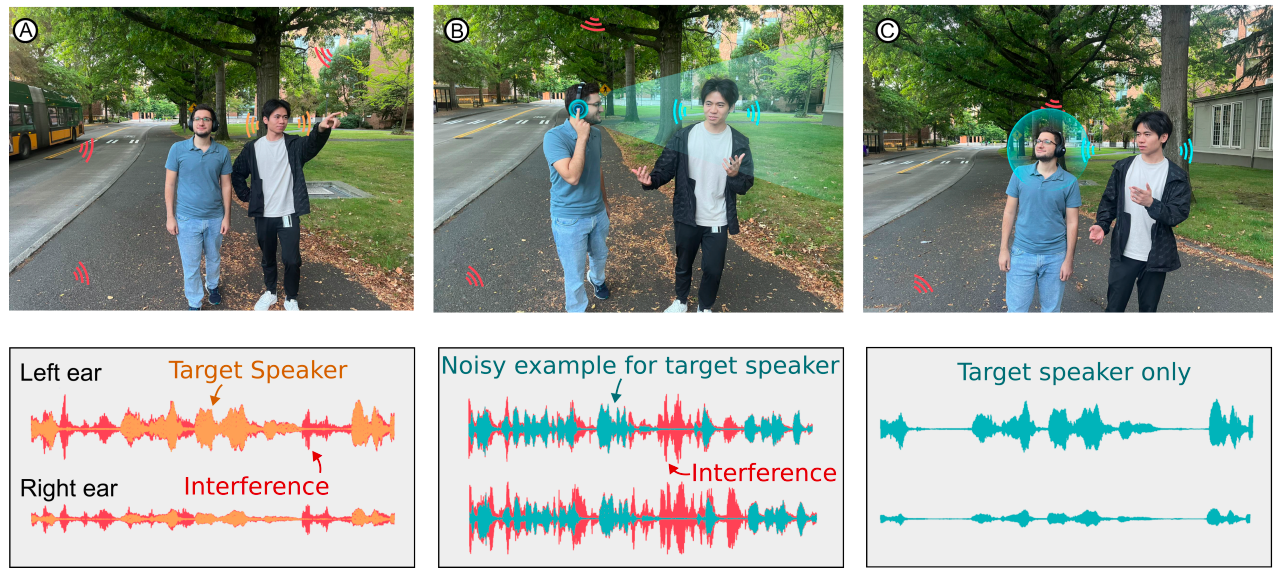
듣고 싶은 사람의 목소리만 들려주는 헤드폰은 어떻게 작동할까요?
- 사용자가 듣고 싶은 사람을 1~4초간 바라보며 버튼을 누른다.
- 헤드폰 양쪽 마이크가 소리를 녹음한다.
- 사용자 정면 방향으로부터 들어온 소리만 대상자로 인식해 골라낸다.
- 딥러닝 모델이 해당 화자의 고유한 음성 특징을 추출한다.
- 이 특징을 기준으로, 실시간으로 들어오는 소리 중 상대의 목소리만 필터링해서 재생한다.
상대의 소리를 한 번 등록해 두면 시스템은 계속 그 사람의 목소리를 따라가기 때문에 자유롭게 고개를 움직일 수 있습니다. 또한 이야기를 나눌수록 선택한 상대의 소리는 점점 정교해진다고 하는데요. 워싱턴 대학과 어셈블리AI(AssemblyAI)의 Target Speech Hearing 연구를 살펴보겠습니다. 🔎 |
|
|
'타겟의 말 듣기' 정도로 해석이 가능한 Target Speech Hearing(이하 'TSH') 연구의 핵심은 깨끗한 음성 데이터 없이도 특정 사람의 목소리만 분리해 낼 수 있다는 점입니다. 그동안은 특정 목소리를 인식하기 위해 조용한 장소에서 녹음된 소리가 필요했는데요. TSH는 자연스러운 소음 속에서도 원하는 사람의 소리를 구별해 냅니다. |
|
|
헤드폰이 작동하는 방식. 목표 화자의 소리와 소음이 함께 녹음된 후, 소리를 분리한 다음 목표 화자의 소리만 재생한다. 출처: 논문
|
|
|
먼저 ‘타겟’을 인식하는 게 우선이지요. 비밀은 바이노럴(binaural) 헤드폰에 있습니다. 바이노럴 헤드폰은 양쪽 귀에 서로 다른 음향을 전달하여 3차원 입체 음향 효과를 제공하는 헤드폰인데요. 헤드폰 양쪽 마이크로 들어온 소리에는 미세한 시간 및 세기 차이가 생깁니다. 정면에서 온 소리는 양쪽 귀에 거의 동시에 도달하고, 방향이 다른 소리는 비대칭으로 들어오지요.
딥러닝 모델은 이 공간적 정보를 바탕으로 정면에서 온 목소리가 목표 화자라고 판단하고, 그 소리를 학습합니다. 이후 실시간으로 들어오는 소리에서도 이 소리와 비슷한 성분만 남기고 나머지는 제거합니다. |
|
|
1. 소리 추출 방식
타겟을 정했으니 그 소리의 특징을 뽑아내야 합니다. 연구진은 두 가지 방식을 실험하는데요.
- Beamforming(빔포밍): 정면에서 들어온 소리를 깨끗하게 복원한 후, 소리를 다시 분석해 화자의 특징을 추출하는 방식
- Knowledge Distillation(지식 증류): 정면에서 들어온 소음 섞인 음성에서 직접 화자의 특징을 추출하는 방식 (자세한 이야기는 밑에서 다룰게요!)
빔포밍 방식은 깨끗한 소리에 비해 약 2.9dB(데시벨) 저하되었습니다. 반면, 지식 증류 방식은 단 0.4dB 성능 저하만 보였습니다. 결국 지식 증류 기법이 TSH에 들어가는 기술로 채택되었지요.
2. 실시간 분리 네트워크
추출한 소리는 어떻게 실시간으로 분리할 수 있을까요?
연구진은 TFGridNet 기반 네트워크를 경량화시킵니다. 간단히 말하면, 추출한 소리를 8밀리초 단위로 잘게 나눠서 실시간으로 분리해서 재생합니다. 전체 지연 시간은 0.018초에 불과해서, 사람이 느끼기엔 거의 즉시 들리는 수준입니다.⚡️
3. 현실 환경 학습
연구실 밖에서도 사용할 수 있어야 유용하겠지요. TSH 기술은 다양한 공간 반향, 움직임, 머리 회전 등을 반영한 데이터로 학습합니다. 최대 18도 고개 방향 오차까지도 허용되도록 설계되어 실제 환경에서도 잘 작동합니다. |
|
|
이번 연구에서 채택된 지식 증류 방식은 다음과 같은 과정을 거칩니다:
- 학습할 때는 큰 모델(teacher)이 깨끗한 음성에서 d-vector를 뽑아준다. 여기서 d-vector란 말하는 사람 고유의 목소리 특징을 숫자로 표현한 값이다.
- 작은 모델(student)은 소음이 섞인 음성 파일을 받으면, 큰 모델이 뽑은 d-vector를 유사하게 따라하도록 학습한다.
- 실사용 시에는 오직 작은 모델만 사용되어, 빠르고 정확한 특징 추출이 가능해진다.
지식 증류 방식은 소음을 제거하고 깨끗한 소리를 복원하는 대신, 소음이 섞인 음성 속에서 '누구의 목소리인지'를 직접 알아내는 것에 초점을 둡니다. |
|
|
한 사람에게 집중했으니, 이번에는 다같이 어울려볼까요? 🥳
이번 연구는 세계 최초로 헤드폰을 통해 여럿이 하는 말을 동시에 번역하면서, 각 사람의 목소리 특성과 방향 정보까지 그대로 유지하는 AI 기술입니다. 워싱턴 대학과 메타AI, 카네기 멜론 등이 함께한 연구인데요. 목소리의 방향, 감정, 말투까지 인식하는, 공간을 아우르는 Spatial Speech Translation(이하 'SST')을 소개합니다. |
|
|
1. 목소리와 위치 파악하기
주변 소리를 10도 간격으로 방향을 나눠서 각기 다른 목소리를 감지합니다.
양쪽 마이크에 들어오는 소리 도달 시간 차이를 이용해 소리가 온 방향을 파악할 수 있는데요. 이 정보를 바탕으로 각 사람의 목소리를 따로따로 분리합니다. 비슷한 소리가 여러 방향에서 겹쳐 들릴 경우에는 소리의 세기를 기준으로 같은 사람의 소리를 하나로 묶습니다.🔊
2. 동시에 자연스럽게 통역하기
목소리를 작은 단위(chunk)로 나눠서 빠르게 번역합니다. 청크 단위로 나누었기 때문에 말이 진행되는 동안 실시간으로 번역할 수 있습니다. 평균적으로 1.3초 가량이 걸린다고 하니, 동시 통역 수준이라고 볼 수 있겠지요?
또한 단어를 하나씩 바꾸는 게 아니라, 문장 구조와 흐름을 고려해서 자연스럽게 말이 이어지도록 번역합니다. 동시에 약 4명까지 통역이 가능합니다.
3. 감정과 말투도 함께 살리기
사람마다 가지고 있는 고유한 발성 습관, 음색, 억양, 속도 등을 숫자로 표현한 값을 생성하는 AI를 사용합니다. 원래는 화자 인식에 사용하는 방식인데요. 이렇게 추출한 정보는 번역된 문장을 음성으로 만들 때 반영되어, 누가 신이 나고 누가 화난 건지 소리로 전달할 수 있습니다.
4. 목소리 방향 보존하기
여러 사람이 말할 때, 누가 어디서 말하는지도 알면 편하겠지요?
목소리의 위치 정보(좌우, 거리)를 반영해서, 실제로 말한 사람의 방향에서 소리가 들리는 것처럼 재구성해줍니다. 왼쪽에서 말하는 사람은 왼쪽 헤드폰에서 들리도록 처리합니다.
덕분에 SST는 동시에 여럿이 말을 해도 각 화자의 말을 따로따로 분리한 다음, 각자의 말투나 감정, 그리고 방향을 반영해 실시간 통역을 제공할 수 있습니다. |
|
|
얼마 전, 구글이 돌고래와 대화하는 AI를 연구한다는 소식이 있었지요. 동시 통역 헤드폰이 다양한 동물의 언어까지 통역해 준다면 어떨까, 즐거운 상상을 해봅니다. 빠른 발전으로 불안을 주기도 하지만, 또 마냥 신기한 소식으로 미래를 기대하게 만드는 AI입니다.✨ |
|
|
구독자님, 재밌게 읽으셨나요?
주변에도 공유해 주시면 정말 감사하겠습니다. 😌
|
|
|
|